
나만의 작은 도서관
[Network] 빅 엔디안(Big Endian)과 리틀 엔디안(Little Endian) 본문
개요
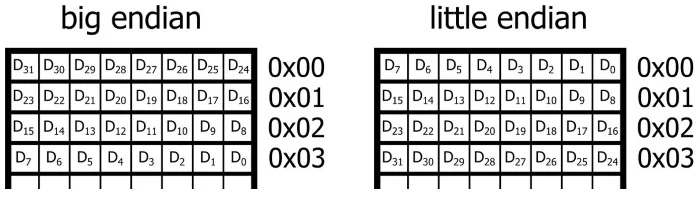
이번에 바이트 배열을 이용한 TCP 통신을 배우던 중 빅 엔디안 방식과 리틀 엔디안 방식이 있다는 것을 알게 되었다. 자주 보던 용어들이니 이번 기회에 글로 정리하였다.
상위 바이트와 하위 바이트
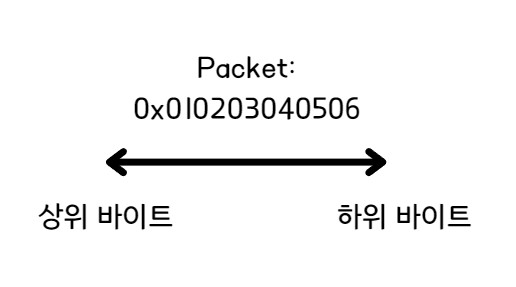
하나의 데이터는 여러 개의 연속된 바이트로 분리되어 저장된다. 이때 데이터를 구성하는 바이트 중 서로 다른 두 바이트가 저장하고 있는 값을 비교했을 때, 값이 큰 바이트를 상위 바이트, 작은 바이트를 하위 바이트라고 부른다. 즉 정리하면 아래와 같다.
- 상위 바이트(High Byte): 다중 바이트 값(데이터)에서 큰 값을 가져 높은 위치(상위 비트)에 있는 바이트
- 하위 바이트(Low Byte): 다중 바이트 값(데이터)에서 낮은 값을 가져 낮은 위치(하위 비트)에 있는 바이트
이때 가장 높은 위치에 있는 바이트를 "최상위 바이트(MSB, most significant byte)"라 부르며, 가장 낮은 위치에 있는 바이트를 "최하위 바이트(LSB, least significant byte)"라고 부른다.
최상위 바이트 주소 = 데이터 시작 주소?
값을 표현할 때 가장 큰 값부터 차례대로 표현하니 데이터를 저장할 때도 최상위 바이트부터 차례대로 저장할 것 같지만, 시스템이 사용하는 메모리 배열 방식에 따라 그렇지 않을 수도 있다. 즉, 시스템이 사용하는 메모리 배열 방식이 "빅 엔디안"인지, "리틀 엔디안"인지에 따라 저장되는 순서가 달라진다.
빅 엔디안(Big Endian)
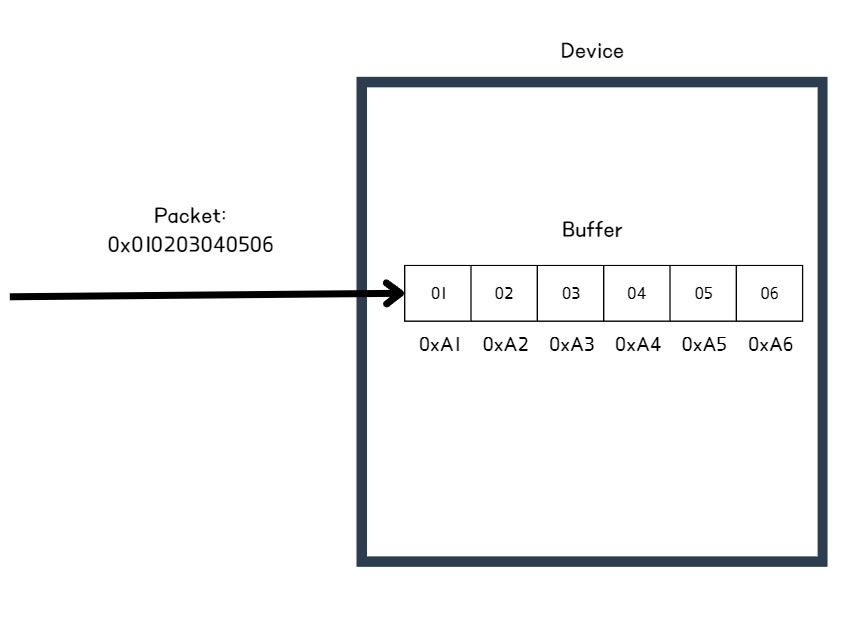
빅 엔디안은 큰 값이 먼저 저장되는 방식으로, 여기서 큰 값은 상위 바이트를 의미한다. 예를 들어 빅 엔디안 방식을 사용하는 시스템에서 패킷을 수신받았다면, 시스템은 최상위 바이트 -> 최하위 바이트 순으로 메모리(buffer)에 저장하며, 결과적으로 데이터 시작 주소에 최상위 바이트 값이 저장되게 된다.
주소: | A | A+1 | A+2 | A+3 |
값 : | 0x12 | 0x34 | 0x56 | 0x78 |
빅 엔디안은 패킷에 담긴 데이터 순서와 메모리에 저장되는 순서가 일치하므로, 1) 사람이 읽기에 더 직관적이며, 2) "네트워크 표준"으로 사용된다.
리틀 엔디안(Little Endian)
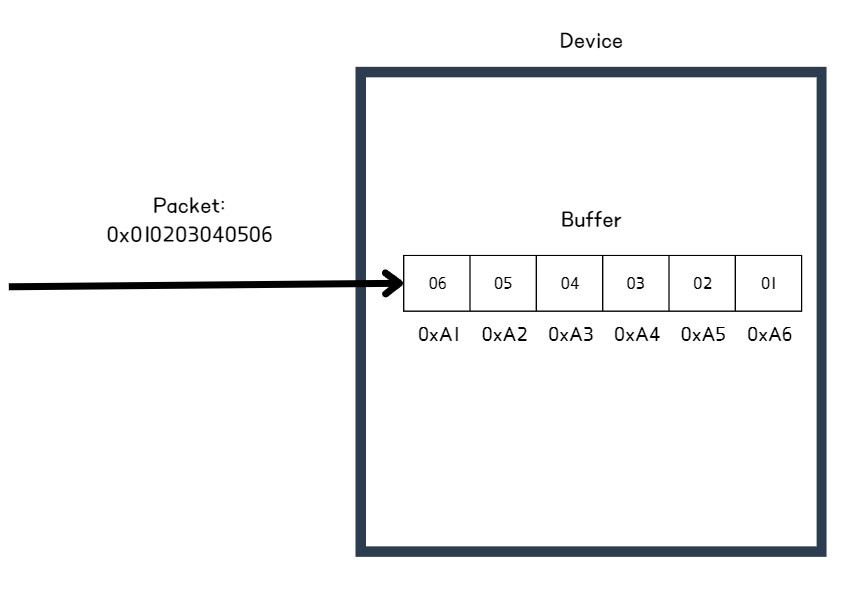
리틀 엔디안은 빅 엔디안과 반대로 작은 값이 먼저 저장되는 방식으로, 여기서 작은 값은 하위 바이트를 의미한다. 예를 들어 리틀 엔디안 방식을 사용하는 시스템에서 패킷을 수신받았다면, 시스템은 최하위 바이트 -> 최상위 바이트 순으로 메모리(buffer)에 저장하며, 결과적으로 데이터 시작 주소에 최하위 바이트 값이 저장되게 된다.
주소: | A | A+1 | A+2 | A+3 |
값 : | 0x78 | 0x56 | 0x34 | 0x12 |
리틀 엔디안은 패킷에 담긴 데이터 순서와 메모리에 저장되는 순서가 달라, 사람이 읽기가 불편하다는 단점이 있지만, 1) 자료형을 작은 타입으로 캐스팅할 때 유리하고, 2) "대부분의 CPU 아키텍처에서 채택하고 있는 방식"이다.
추가로, "CPU가 덧셈, 뺄셈 등 연산에서 하위 바이트부터 계산하므로, 리틀 엔디안이 carry 판단(자리 올림 수 판단)에 유리하다"는 이야기가 있지만, 현시점의 CPU 아키텍처에서는 이것이 성능상의 유의미한 이점이 되지는 않는다고 한다.
리틀 엔디안 vs 빅 엔디안 정리

빅 엔디안 vs 리틀 엔디안 정리표
| 특징 | 빅 엔디안(Big Endian) | 리틀 엔디안(Little Endian) |
| 저장 순서 | MSB → LSB | LSB → MSB |
| 사람이 읽기 쉬움 | ✅ 읽기 쉬움 | ❌ 읽기 어려움 |
| CPU 연산 효율성 | ❌ x86에서는 비효율적 | ✅ x86, ARM에서 최적화 |
| 네트워크 표준 | ✅ TCP/IP 표준 | ❌ 변환 필요 |
| 대부분의 현대 CPU | ❌ 일부 프로세서(IBM, SUN, PowerPC) | ✅ x86, ARM (대부분) |
| 메모리 확장 | ❌ 상위 바이트 접근 시 추가 연산 필요 | ✅ 하위 바이트 접근 용이 |
혼용 금지
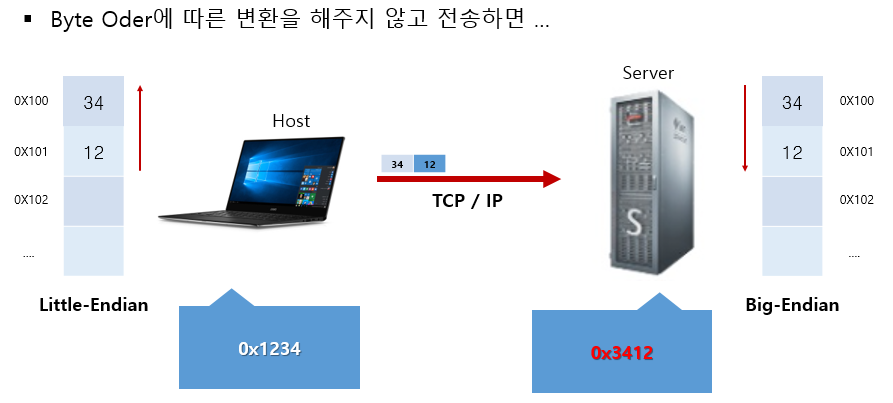
TCP 통신을 하는 과정에서 각 터미널이 서로 다른 엔디안 방식을 사용하면 문제가 발생한다. 위 그림과 같이 클라이언트-서버 구조에서 클라이언트가 리틀 엔디안 방식으로 "0x1234"를 보냈을 때, 서버는 " 0x1234"가 아닌 "0x3412"로 해석하기 때문이다.
네트워크 표준으로 빅 엔디안을 사용하도록 되어있기 때문에 리틀 엔디안으로 통신하려는 기기는 드물겠지만, CPU 종류마다(빅 엔디안: Sparc, 리틀 엔디안: Intel) 사용하는 기본 엔디안 방식이 다르기 때문에 이로 인한 엔디안 혼용 사용을 조심해야 한다.
Node.js에서 빅 엔디안/ 리틀 엔디안 설정
Node.js에서는 Buffer라는 객체의 readUInt16BE()와 같은 메서드를 통해 빅 엔디안/ 리틀 엔디안 방식을 설정할 수 있다. (바이트 크기 또한 설정할 수 있다). readUInt16BE(start_pos)의 뜻은 다음과 같다.
- read: 버퍼에서 데이터를 읽겠다.
- UInt: unsigned int 타입
- 16: 16비트 = 2Byte
- BE: Big Endian
- start_pos : 시작 위치(바이트 단위)
즉, readUInt16BE(start_pos)는 "버퍼에서 start_pos바이트부터 unsigned int 타입의 2Byte 크기를 가진 데이터를 빅 엔디안 방식으로 버퍼에서 읽겠다"라는 의미가 된다. 간단한 사용법 코드는 다음과 같다.
import { TOTAL_LENGTH_SIZE, HANDLER_ID } from './constants.js';
export const readHeader = (buffer) => {
return {
length: buffer.readUInt32BE(0),
handlerId: buffer.readUInt16BE(TOTAL_LENGTH_SIZE),
};
};
참고 자료
'Common > CS-네트워크' 카테고리의 다른 글
| [Network] 블로킹/논블로킹 방식, 동기/비동기 방식 (0) | 2025.01.11 |
|---|---|
| [Network] protoBuf와 직렬화/역직렬화 (1) | 2024.06.28 |
| [Network] TCP vs UDP (1) | 2024.06.28 |
| [Network] 1분 간단 질문. TCP Handshake란 무엇인가요? (0) | 2024.06.27 |
| [Network] 대칭 키 암호화 방식과 공개 키 암호화 방식 (0) | 2024.06.26 |



