
나만의 작은 도서관
[C++][Build] 전처리 단계 - 전처리기 지시문(preprocessor directive) 본문
C++/문법 및 메소드(STL)
[C++][Build] 전처리 단계 - 전처리기 지시문(preprocessor directive)
pledge24 2025. 4. 14. 16:35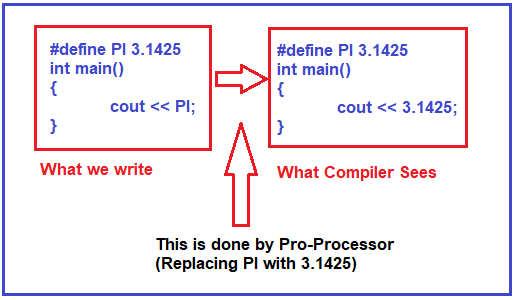
전처리기 지시문(preprocessor directive)이란?
- 전처리기 지시문은 전처리 단계에서 전처리기(preprocessor)에 의해 처리되는 명령어로, 명령어들은 모두 ‘#’ 기호로 시작한다.
- 전처리기 지시문을 활용하면 파일 포함, 조건부 컴파일, 매크로 정의 등 다양한 작업을 수행할 수 있다.
대표적인 전처리기 명령어
- #include
- #define
- #ifdef, #ifndef
#include
#include "path-spec" // 사용자 정의 파일 추가 방식
#include <path-spec> // 표준 라이브러리 추가 방식- #include는 전처리기 지시문 중에서도 가장 자주 사용되는 명령어로, 지정한 파일을 현재 소스 파일에 추가한다.
#include가 파일을 추가하는 방식
- #include가 실행되면 지정한 파일의 모든 내용이 #include 위치에 그대로 "복사"된다. 복사된 내용은 기존 파일과 독립적으로 존재하기 때문에, 복사된 내용에 정의된 변수의 메모리 또한 독립적인 공간을 가지게 된다.
- 만약 아래와 같은 두 헤더 파일이 존재한다면,
// a.h
void funcA();
int varA;
// b.h
void sayHello();
int varB;- 두 헤더 파일을 #include 한 main.cpp의 변화는 아래와 같다.
// -----#include 실행 전 main.cpp-----
#include "a.h"
#include "b.h"
int main() {
sayHello();
return 0;
}
// -----#include 실행 후 main.cpp-----
void funcA();
int varA;
void sayHello();
int varB;
int main() {
sayHello(); // 호출 시 이동할 위치를 연결하는건 링킹 단계에서 진행됨.
return 0;
}
꺾쇠(<>) 방식과 따옴표(””) 방식의 차이
- #include를 통해 지정된 파일을 가져올 때 꺾쇠(<>) 방식과 따옴표(””) 방식으로 가져올 수 있다. 두 방식의 차이점은 경로가 불완전하게 지정되었을 때 전처리기가 검색하는 경로의 순서가 다르다는 것이다.
- 두 방식의 차이에 대해 간단히 요약하자면 아래 표와 같다.
| 구분 | 검색 순서 | 용도 |
| 꺾쇠 괄호 < > 형식 (#include <파일명>) | 시스템 또는 설정된 경로들부터 먼저 찾는다. | 시스템이나 표준 라이브러리 헤더 파일을 포함할 때 사용한다. ex. #include <iostream> |
| 따옴표 " " 형식 (#include "파일명") |
현재 파일과 관련된 디렉터리부터 먼저 검색하고, 없으면 시스템 디렉토리에서 찾는다. | 사용자 정의 헤더 파일을 포함할 때 사용한다. ex. #include "myheader.h" |
#define
#define 식별자(identifieropt, ... , identifieropt) token-string opt- #define 지시문은 컴파일러가 원본 파일에서 식별자가 발생할 때마다 토큰 문자열(token-string)을 대체한다.
- 즉, #define으로 정의한 식별자를 지정한 “문자열”로 치환한다고 보면 된다.
- #define을 정의할 때 여러 줄을 사용하고 싶다면, 백슬래시(’\’)를 문장 끝마다 붙여 확장한다.
- 식별자 뒤에 ()를 붙이면 매크로 함수로도 사용할 수 있다.
#define 예시
// #define 기본 형태
#define MAXN 1'000'000
// #define 매크로 함수
#define SAYMESSAGE(str) std::cout << "message: " << str << std::endl;
// #define 여러 줄로 확장(백슬래시('\\') 활용)
#define CRASH(cause) \\
{ \\
uint32* crash = nullptr; \\
__analysis_assume(crash != nullptr); \\
*crash = 0xDEADBEEF; \\
}
토큰 붙여 넣기 연산자 ##
- 토큰 붙여 넣기 연산자인 ##을 활용하면 이어지지 않은 두 토큰 문자열을 하나로 합친다.
- 예를 들어, A##B처럼 되어있다면, 이는 전처리 단계 이후 AB가 된다.
- 주로 매크로 안에서 변수 이름을 동적으로 만들 때 사용된다.
#define USING_SHARED_PTR(name) using name##Ref = std::shared_ptr<class name>;
USING_SHARED_PTR(IocpCore);
// => using IocpCoreRef = std::shared_ptr<class IocpCore>;
#define보다 enum을 사용하는 것이 좋은 이유
- #define을 사용하면 식별자가 문자열로 치환된 상태에서 컴파일되기 때문에 디버깅 시 해당 내용에 대한 추적이 어려워진다.
- 따라서 디버깅 시 이름과 값 추적에 용이한 enum이나 enum class를 사용하는 것이 권장된다.
#define MODE_PLAY 0
#define MODE_STOP 1
enum class Mode
{
Play = 0,
Stop = 1
};
int main(void)
{
MODE_PLAY; // 전처리 단계 이후 0으로 치환됨
Mode::Play; // Mode::Play라는 코드가 유지됨
return 0;
}
#ifdef, #ifndef
#ifdef 식별자 // => "#if defined 식별자"와 동일
#ifndef 식별자 // => "#if !defined 식별자"와 동일
#endif- #ifdef 지시문은 조건부 컴파일 지시문 중 하나로, 특정 식별자가 정의되어 있는지 확인해서 코드 일부를 포함하거나 제외하기 위해 사용한다.
- #ifdef 이후의 코드는 식별자가 #define으로 정의되었을 때 활성화되며, 반대로 #ifndef 이후의 코드는 식별자가 #define으로 정의되어있지 않을 때 활성화된다.
- 비슷한 계열인 #if - #elif - #else 지시문들과 혼용해서 사용하기도 한다.
- 활성화되는 끝 범위는 #endif를 통해 표시한다.
#ifdef 예시
#define DEBUG // DEBUG를 #define으로 정의(빈 문자열로 치환됨)
#ifdef DEBUG
std::cout << "DEBUG 모드입니다." << std::endl;
#elif defined(REALESE)
std::cout << "REALEASE 모드입니다." << std::endl;
#endif
// 실행 결과 => "DEBUG 모드입니다."
#ifndef를 활용한 헤더 가드(Header Guard)
// "a.h" 해더 파일
#ifndef A_H // A_H는 a.h 헤더 파일을 의미
#define A_H
// 헤더에 포함된 코드...
class A {};
#endif- 하나의 소스 파일에 같은 헤더 파일이 중복 포함될 경우, 1) 같은 내용을 여러 번 파싱하여 빌드 시간이 길어지거나, 2) 헤더에 포함된 변수, 함수, 클래스 등이 여러 번 정의되어 중복 정의 오류를 발생한다.
- 이러한 문제를 방지하기 위해 헤더 파일의 중복 포함을 막아주는 "헤더 가드"가 필요하며, 헤더 가드는 #ifndef를 활용해 구현할 수 있다.
- 참고로 헤더 가드를 추가했을 때 1) 문제를 해결하여 얻은 이점을 “다중 포함 최적화”, 2) 문제를 해결하여 얻은 이점을 “ODR(One Definition Rule) 위반 방지”라고 한다.
- 헤더 가드 역할로썬 #pragma once가 더 간편하기 때문에, 최근에는 #ifndef보단 #pragma once를 더 자주 사용한다.
#ifndef를 이용한 헤더 가드 패턴 예제
- #ifndef는 a.h 헤더 파일이 정의되지 않았을 때만 a.h를 #include 하므로, 아래 코드에서 두 번째 #ifndef의 #include 구문은 실행되지 않는다.
// -----#include 실행 전 main.cpp-----
#include "a.h"
#include "a.h"
int main() {}
// -----#include 실행 후 main.cpp-----
#ifndef A_H
#define A_H // => 실행 O
// 헤더에 포함된 코드...
class A {};
#endif
#ifndef A_H
#define A_H // => 실행 X
// 헤더에 포함된 코드...
class A {};
#endif
int main() {}
이외에도 많은 전처리기 지시문들이 있다.
- 다른 전처리기 지시문에 대한 자세한 내용은 아래 링크를 확인하면 된다.
https://learn.microsoft.com/ko-kr/cpp/preprocessor/preprocessor-directives?view=msvc-170
전처리기 지시문
자세한 정보: 전처리기 지시문
learn.microsoft.com
참고 자료
https://learn.microsoft.com/ko-kr/cpp/preprocessor/preprocessor-directives?view=msvc-170
'C++ > 문법 및 메소드(STL)' 카테고리의 다른 글
| [C++][Build] 컴파일 단계 - 번역 단위(translation unit)와 선언과 정의, 그리고 ODR (0) | 2025.04.14 |
|---|---|
| [C++][Build] 전처리 단계 - #pragma 지시문 (0) | 2025.04.14 |
| [C++][Build] 빌드와 빌드의 각 단계 (0) | 2025.04.14 |
| [C++] extern 키워드와 전역 변수 (0) | 2025.04.09 |
| [C++] 스마트 포인터(Smart Pointer) (0) | 2025.04.06 |
'C++/문법 및 메소드(STL)' Related Articles
more



